
�����������������Ź��ں� ������Pro�����ߣ�Yoky����Ȩվ�L֮��ת�ط�����
7��23�գ����Yͨ�x�F���ʽ�l��Qwen3-Coder-480B-A35B-Instruct���@������AI���������һ����ˮ��ʱ�̡���ģ�Ͳ���480B�ܲ�����35B�����MoE�ܹ���ԭ��֧��256K�����ģ�����չ��1M token����Agentic Coding��Browser-Use��Tool-Use��������ж�������Ŀ�ԴSOTA������ֱ�ӶԱ�Claude Sonnet-4��
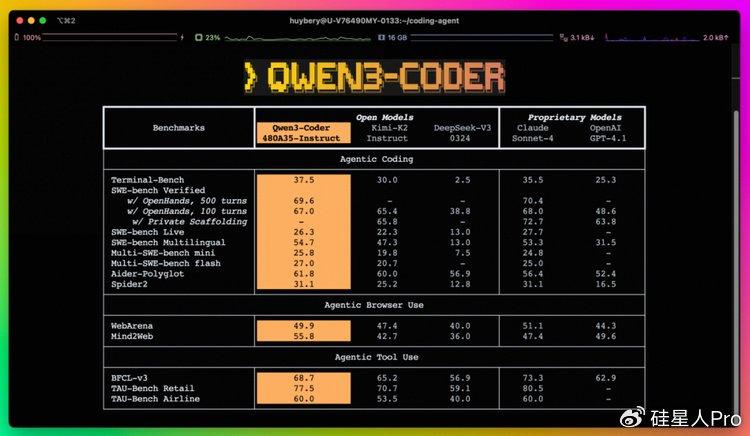
��ͬ��������Ҫ�������õĴ���ģ�ͣ�Qwen3-Coder���������ˡ�һ������ӹ���������ֿ⡱��ͬ����Դ��CLI����Qwen Code����ģ������������Ա��һ������������������������ӱ�д���뵽�ܲ�����bug���������������˹����и�Ԥ������Agentic Coding��ʽ�Ѵ�ģ�͵���һ�����ڲֿ��������ж���Agent������������Ȼ�����������ܵ���Git����������ն˵ȹ��ߡ�
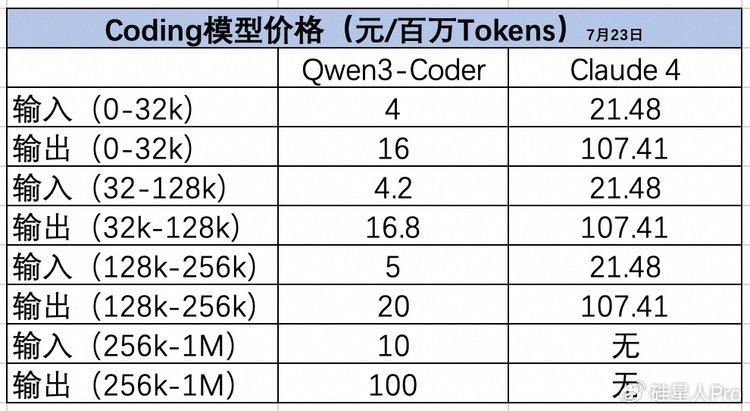
���P�I���ǃr�ݘO�����@��ÿ���fTokens������������۸�ֱ�Ϊ4Ԫ��16Ԫ��ƽ���۸�ΪClaude4��1/3��ͬʱ�������ư������Ƴ��˵���5�۵���ʱ�Żݣ�128K-1M�������ļ۸����������Żݡ�������ȫ��Դ������õ����ߣ���ԭ���߰���AI���̷�������ƽ��
�ܶ��˿��ܻ�û��ʶ��AI Coding��������ֵ��������ֻ��д����Ĺ��ߣ�����AI Agent�������������ɽ����Ĺؼ��ײ㼼����������Ƕȿ���Qwen3-Coder�ķ���������־��AI���������ӡ��������ߡ�������Agent����ԾǨ������Դ+���ͼ۵���ϣ����ܻ����������������ռ����ı�����������������Ϸ����
�҂�����һ�r�g��ɃȜy������l���ļ��g�����M�н��x��
ʵ��Agentic Coding
�ڌ��y�A�Σ��҂��K�]���x���ѽ����yԇ�^��݆��؝���ߡ������[�����x����Ҏ�t���}�s������Ҳ����ć��匦���[���҂���Prompt��:����һ�����匦��С�[���Еr�gӋ�r�����؇����[���Ҏ�t������ӡ������c����
����һ���\�Еr���Y�����H�M���ˇ���������Ҏ�t��Ҳ�_�����˳��ӡ������c��Ҏ�t�����ӱ������ᣬ��ǰλ�ý�ֹ�����ӣ���Ҏ�t�����@չ�F��ģ��������͌��F���A�[��߉�����������
���ǣ��@�����匦���[��߀��̫�^�ں��Σ�����ȱ��ݔ�A�ЙC�ƣ�ȱ�ٵ�Ӌ�r�ȵȡ��[��������Ժ��Ñ��w�����кܴ��������g���@Щ���܌���һ�������ć����[����f�DZز����ٵġ�
��ˣ��҂�������һ��:����һ�����匦��С�[���Еr�gӋ�r�����؇����[���Ҏ�t������ӡ������c����߀�����քݷ������Д�ݔ�A��
Qwen3-coder�o���˸��}�s��Ҳ��������[����棬�����ڛ]����ʾ��ǰ���£��o�����Jݔ�İ��o������һ�����}�LJ������Ӵ�Ҏ�t�������҂���Prompt���ᵽ��Ҏ�t��һЩ�������硰��١���Qwen3-coderû����ȫд������
�������������ֳ�����ģ��������һ����ҳ��Prompt��:����һҳ�� HTML+CSS+SVG ���λû�ɫ��ҳ:������ #FFF59D �� #FFEB3B ����;60�Ű�ɫ����6��Ư��;5����������ѭ�����뵭��;���� ��Dreamy Lemon�� ��д�ִ�����;�㿪���ʻ�ը��������Ԫ�ر������ʻ�+Tiffany�����}�������ֱ�����С�
�Y�����ϣ�ģ�ʹ_������ָ��F�����еļ��gҪ��:����u׃���������ӄӮ�������Ч�����l�����֡��������ܵȵȡ�Ȼ�������ڡ����á��@������������ƺ����F��ƫ����܌�����x����Ҫ����ģ��Ч��������ҕ�X�V�R���������wҕ�XЧ���m���䷴��������涼ģ�����壬
�҂�Ҳ�yԇ�˹ٷ��l���������\�ӈ�����ֻ���^�҂��x���˷dz��}�s�ġ����w�\�ӡ����y���Ϻܠ��yģ�ͣ��҂�ͨ�^Cline�{��Qwen3-Coder��yԇ����Agent������
Prompt:��һ��ʵʱ�������˶�����ɫȫ�� ;3����ɫС�졢�̡�����ֻ�ܱ˴������������ã��˴����������ơ����䣬������ʵ�˶�;ʵʱ����ţ���������� F = G��m?m?/r?���ٶ�ʸ����ʱ���ۻ�;�����ʺ罥��켣(800�� FIFO)���ɿ���;���Ͻ��ṩ:�����������ˡ��ٶȱ��ʻ��ˡ��켣��ѡ�����ð�ť;�����������Ƽ��á�˫�����������������3������˶���
https://weibo.com/tv/show/1034:5191880476917785?from=old_pc_videoshow
�@�Σ��҂���ȡ�˽�Ӗ���M���ܵ�������prompt������ģ�ͣ��҂��l�FQwen3-Coder����ɾ����ᣬ�{����Chrome��[�����ߣ�����̨������ʾ��һ�飬�K�ˌ������������Ҫ���������z�y�ꮅ�ᣬ���M�뵽��K��ʾ�A�Ρ�
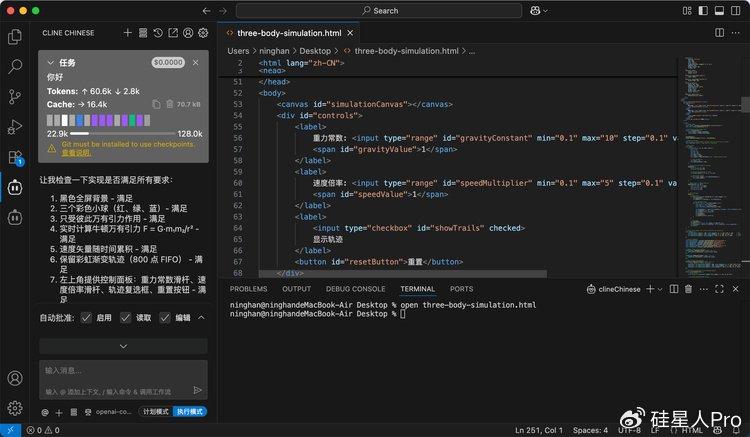
��Ȼ�����H�����е����w�\�ӿ϶�����ʾ�����}�s���@Ҳ��ζ�����mȻģ���܉�����K�����}�s�������б������ڌ��@Щ�����D�����ɹ����Ĵ��a�r���e���漰�}�s���WӋ��͌��r�Ӯ��IJ��֣�߀Ҫͨ�^��߅fͬ����ɡ�
������a�������L����ģ���Y?
Qwen�ŶӲ�����һ��ȫ�µ�ѵ��˼·:����û�а�Agent�����������ڵġ��������������ѵ�������о���ȼ��ɡ�ͨ��Agent RLѵ����ģ��ѧ���������Ķ��ֽ��������ߵ��á�����������������Щ�����ǡ�������ģ����ģ���������ҵġ�
���AӖ���A�Σ��F�����7.5�f�|token�Ĕ���������70%�Ǵ��a���@��ֻ�Ǻ��εĔ����ѷe��������o�W������S���̲ĵIJ��ԣ��ȱ��C�����������ֲ��G��ͨ�õ��Z�Ժ͔��W������
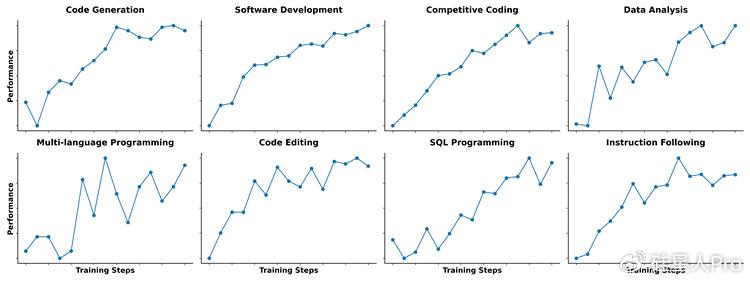
���P�I����������������������ģ��ԭ��֧��256K�������L�ȣ����ɔUչ��1M���@ģ����ͬ�r�鿴�����Ŀ�Ĵ��a������ֻ�ǿ�Ƭ�Ρ�ͬ�r��������֮ǰ��Qwen2.5-Coder�����������I�����ѵ��|���Ĵ��a����������ϴ�Č����_��Ӗ�������|�����@�N�����w�F�ˏ���Փ�W��������D׃��
���y���aģ����Ҫ�Pעbenchmark���F����Qwen�F�����Ӗ���A�μ����ˈ����ӵď����W��������ᘌ����y��������C�����挍�΄գ��Μy���_����С���ߣ��Ԅ��������ɜyԇ�������ш��гɹ��ʮ���������̖��ģ���ڰ��f�������aƬ���Y���}ԇ�e�����Ҽm�e��
�@�N�����ĺ��IJ����:��ֻ��ģ�͌����a������Ҫ�������a�������\�гɹ���ͨ�^�Ԅ����ɴ����yԇ������ģ�Ϳ�������֪���Լ����Ĵ��a��������Ȼ�����M��ģ�͵�Ŀ�ˏġ��ܷ֡��D���ˡ����á���
���Mһ����������Agent�������ڲ������y�Юb���ġ��F���SWE-Bench�@���Ҫ��݆�Ĵ��a���ܜyԇ����Git�ύ�ĭh���Y�������W�����@�ѽ��ӽ��挍��ܛ���_�l���̡�
����ͻ�����ڻ����Ĺ�ҵ����չ�������ð����ƹ�������ͬʱ����2���������̻�����ϵͳ������ͬʱ��2����������ģ����ϰ��̡�ÿ�����������ṩ��ʱ������ģ����ʵϰ����Աһ�����Ͻ���CI�������ٸ����ܣ�������SWE-Bench Verified���¿�Դ��һ��
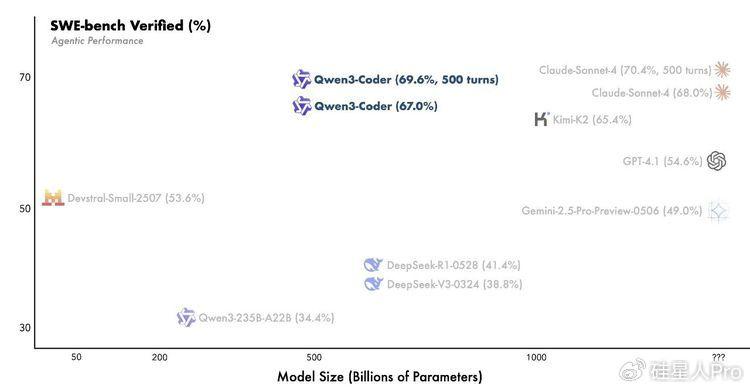
����ʵ������ѵ��������Qwen3-Coder�������AI���̹�������ͻ�����ռ������ƿ��:������������ǰ��AI���������ձ����һ����������:�������ɺ��������bug������������Ҫ�ֶ��Ų��������Ա�̾���Ҫ���O������ͨ�Ñ������s������Qwen3-Coder�߂����Ҝyԇ���{ԇ���������������ˡ����꼴���á����@��ζ����ʹ�Ǿ�������Ҳ�ܽ���AI����}�s���_�l�΄ա�
����Ҫ���dzɱ����ݎ������Ј����ܡ��_�l�^����������Ҫ��݆�����{ԇ������ʹ��Claude4�@�피�ģ�ͳɱ��߰����S����С�F͂����_�l��ֻ�������d�U��Qwen3-Coder�ڱ�����ͬ����ˮ��ǰ���£��ɱ��H������֮һ��������ȫ�_Դ���M���ã��ص������˳ɱ��T�����@�N�����c�r�������ƽ�⣬��������ٳɠ��_�l�ߵ����xģ�͡�
Qwen3-Coder�ĺ��ă��ݲ��H���ھ��������������������䏊���Agent���ԡ�ԓģ���܉������{�ø��N���ߡ������}�s�����M�ж�݆�������@�N�����h�����y�Ĵ��a�aȫ���ߡ�
Ȼ������ǰ�г���AI Coding���ӳ̶�ԶԶ������ʵ���ϣ����������AI Agent�ĺ��Ļ�������AI�������������ɽ�����ؼ��ĵײ㼼������AI�ܹ���������д���롢���ù��ߡ������쳣ʱ�����;߱�������ʵ�����������ж��������������ά�ȿ���AI Coding�ļ�ֵ�����ص��ˡ�
�C�ϸ����������Qwen3-Coder�����f��Ŀǰȫ���ȣ�����ԃr�ȵľ���ģ�͡����H�ڼ��g�����ό���피���Դģ�ͣ��ڳɱ������ϸ���ʵ���������������ƣ�������ȫ��Դ�IJ��ԣ��������¶���AI���̹��ߵ���ҵ����
�����̵��T����AI�ص��͕r���҂�������������ܛ���_�l���B����������������
���e��