
���죬�ٶ������ǧ����ʽ�Ƴ�ȫ��ҕ�X����ģ������Qianfan-VL���Kȫ���_Դ!ԓϵ��ģ�Ͱ���3B��8B��70B�����ߴ�汾����������I����ģ�B��������������������Ż����Ӿ������ģ�͡���������10��10�գ��û����ڰٶ������ǧ��ƽ̨�������8B��70Bģ�͡�Qianfan-VL�����߱���ɫ�Ļ���ͨ������������Բ�ҵ����еĸ�Ƶ������OCR�ͽ�����ֱ��������ר��ǿ����ʹ����ʵ��Ӧ���б��ָ���Խ��
Qianfan-VLϵ��ģ�����ɰٶ������ǧ��ģ���з��Ŷӣ����ڿ�Դģ�ͽ��п��������ڰٶ���������о P800�����ȫ���̼�����������оP800�ṩ��ǿ�������֧�ţ�ȷ��ģ���ܹ���Ч�������������븴���㷨��ͬʱ֧�ֵ�����5000����ģ�IJ��м��㡣��һ��ϲ����Ż���ģ�ͼ����Ч�ʣ���ʹ��ģ�������ܱ����ϴﵽ���µĸ߶ȣ���ͨ�úʹ�������������չ�ֳ�SOTAˮƽ��Qianfan-VLģ���߂��������c:
��ߴ�ģ�͝M�㲻ͬ��������:�ṩ3B��8B��70B���NҎ���ģ�ͣ���ͬҎģ����I���_�l�߶����ҵ����m�Ľ�Q������
�ṩ˼����������:8B��70Bģ��֧��ͨ�^����token����˼�S����������w�}�s�D�����⡢ҕ�X���������W���}�ȶ�N������
OCR�c�ęn������������:����OCRȫ�����R�e���}�s�����ęn����ɴ���ɫ�������ڶ�헻��yԇ�б��F����������I�������ṩ�߾��ȵ�ҕ�X�����Q������
1��ģ�������cЧ��
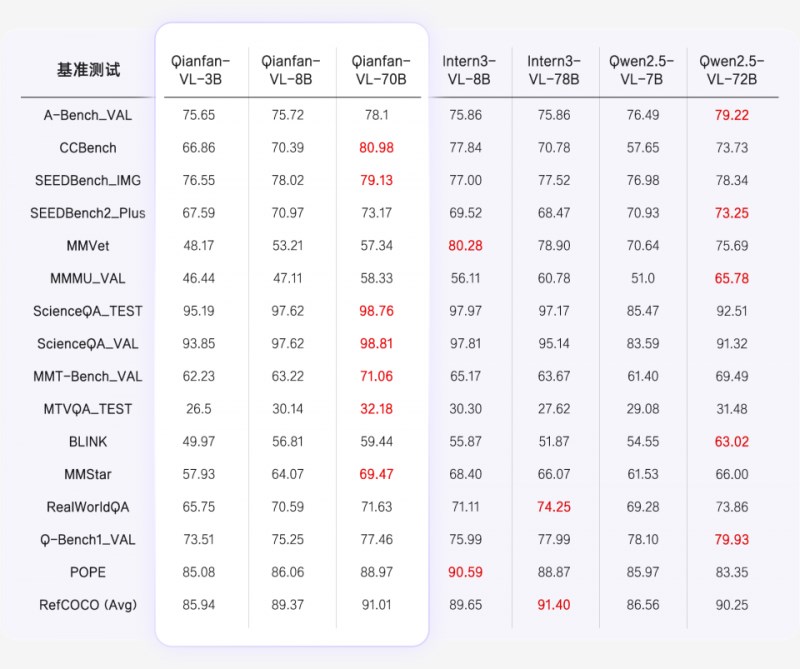
��1��ͨ���������yԇ���F
��ͨ�������������У�Qianfan-VL ϵ��ģ�ͣ�3B��8B��70B��չ�ֳ������������ơ����Ӿ����רҵ�����ʴ�ģ�������������ģ�����������������ֳ��ܺõ�Scaling���ơ��� ScienceQA ��רҵ�ʴ�����У����ȱ���ͻ��;��ģ̬������ RefCOCO �ȣ�����ʶ���������������;ͬʱ���ڸ���ͨ�û�������������ģ�ͣ��������Ҳ��Ϊ���ۣ�������Գ����Ӿ�����ͨ�������ϵij�ɫʵ����Ϊ��ͬ�����µ�����Ӧ���ṩ������֧�š�
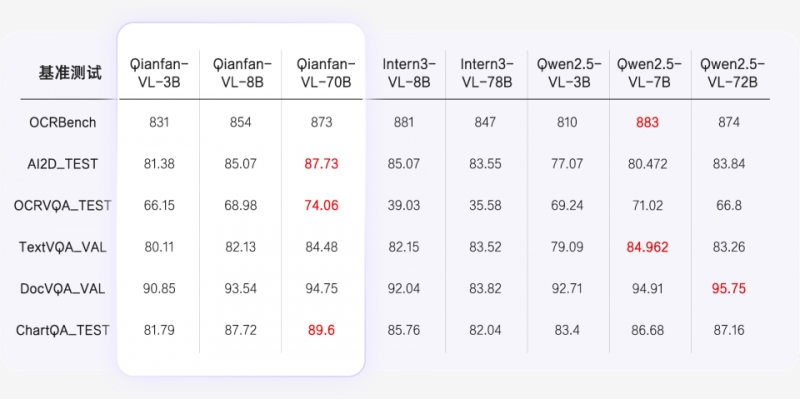
��2��OCR�c�ęn������yԇ���F
Qianfan-VLϵ��ģ�ͣ�3B��8B��70B���� OCR ���ĵ�����������Խʵ����һ���棬�߱�OCRȫ����ʶ���������ܾ�ʶ����д�塢��ѧ��ʽ����Ȼ�������֣����ɶԿ�֤Ʊ����Ϣ���нṹ����ȡ;��һ���棬���Ӱ����ĵ���������ͻ�������Զ���������Ԫ�أ�����������ͼ����ʵ���ĵ������ʴ���ṹ���������ӻ����Ա��ֿ����� OCRBench������רҵ�����У����������ģ�ͣ��ɼ��������������ģ����������ã�Ϊ��ҵ��Ӧ���ṩ�˸߾��ȵ��Ӿ������������������ƶ��ĵ����ܴ��������ĸ�Ч��ء�
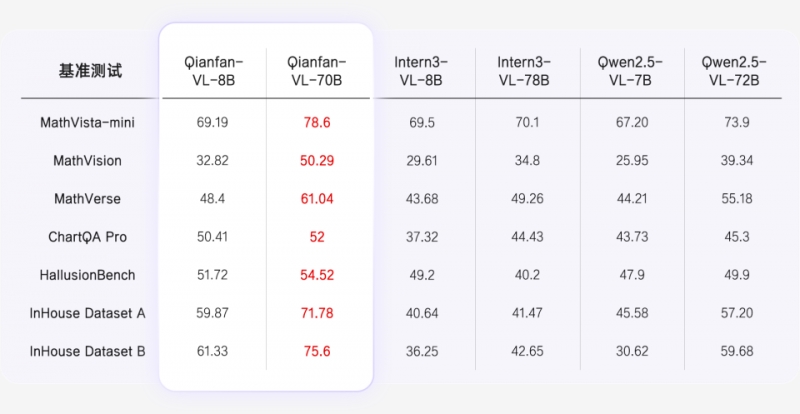
��3�����W���}���yԇ���F
Qianfan-VLϵ�е�8B��70Bģ�ͣ���˼����������������FԽ������֧��ͨ�^����token����˼�S��������ܸ��w�}�s�D�����⡢ҕ�X���������W���}�ȶ�������@��΄���Y��ҕ�X��Ϣ�c�ⲿ֪�R�M�нM����������ģ��ͨ�^�ںϴ���ҕ�X��ı�����픵���K������Ӗ������benchmark���F����������Ӌ�����P�΄�Ч���@��������
�ں�������Ӧ�ó����ϣ�����ͼ���������������棬�ɴӸ���ͼ����ȡ�ؼ���Ϣ���������ݷ���������Ԥ�⡢����������ͳ�Ƽ���;��ѧ�������Ӿ�����������ʵ�ּ�����������ʽʶ�𡢷ֲ���������ƶϡ��Ӕ��W���}���yԇ���F������MathVista-mini��MathVision�ȶ�������У����������ģ�ͣ��ɼ��������������ģ����������ã�Ϊ�������������µ�Ӧ���ṩ��ǿ��֧�֡�
2��ģ�ͼܘ��OӋ�c���g��ɫ
Qianfan-VLͨ�^���M�Ķ�ģ�B�ܘ��OӋ���{����m�AӖ���������g���£����F���I��������ͨ��ҕ�X-�Z��������
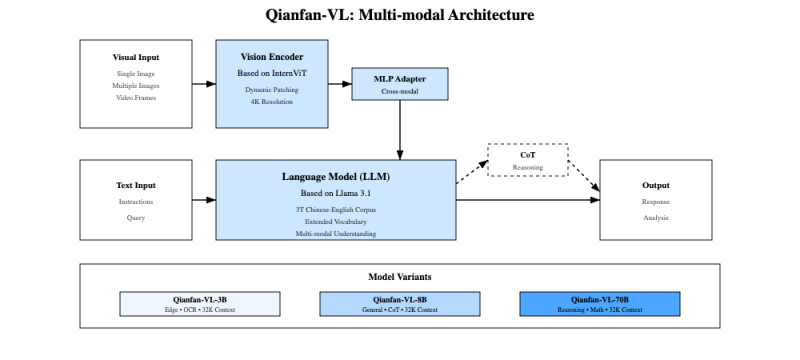
���w�ܘ�
��������Ӗ������:���µ����A��Ӗ�����ԣ��ڱ���ͨ���������A�ό��F�I�������@������
�߾��Ȕ����ϳɹܾ�:���������ģ�B�΄յĴ�Ҏģ�����ϳɹܾ������w�ęn�R�e�����W���}���D�����⡢�����R�e����ʽ�R�e����Ȼ����OCR�Ⱥ����΄գ�ͨ�^�������Ĺܾ��OӋ�����g�^�̔������죬���F���|��Ӗ��������Ҏģ�����b��
����о�Ӵ�ģ��ЧӋ��:���ڰٶ���������оP800оƬ�������˘I���I�ȵij���Ҏģ��5000�����ֲ�ʽӋ��ϵ�y��ͨ�^���µāK�в��Ժ����Ӄ������@��������ģ���΄յ�̎�������c�\��Ч�ʡ�
3��ģ�͑��ð���
��1��OCR�R�e����



��2�����W�������

��3���ęn�������
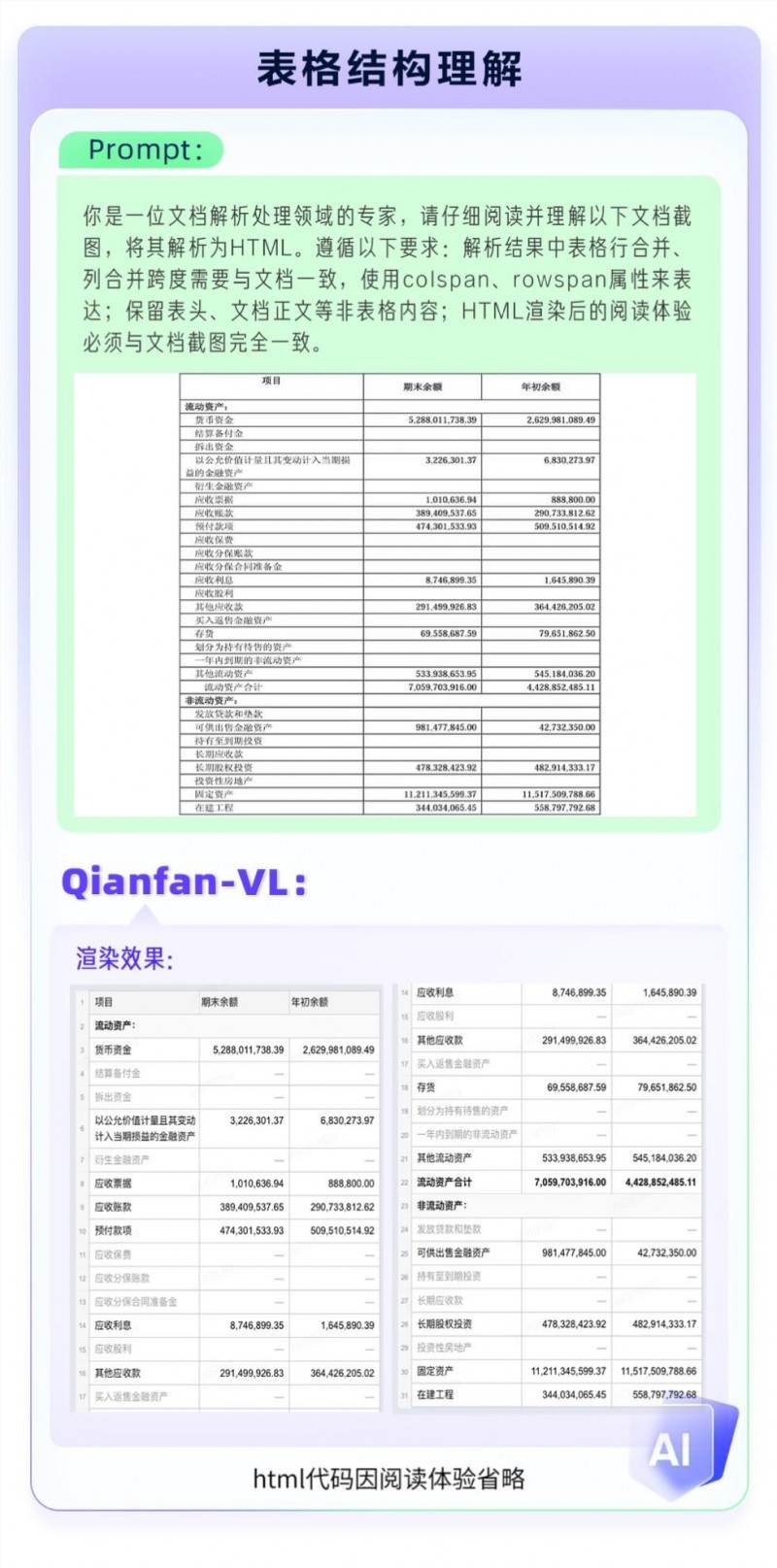
�������������ð����⣬Qianfan-VLͬ�ӿɑ����ڈD��������ҕ�l����Ȉ����У����ʬF��Խ��ģ��Ч����
Qianfan-VLϵ��ģ�͵Ŀ�Դ���ٶ������ǧ����˵�������ǡ���ģ�ͷŽ���ʵ����������������һС��;δ�����ٶ�����녕������������g�Ĉ������c�����È�������ȶ��죬�����Ƴ�ȫ�µĮb�I��ģ�ͣ�ȫ��λ����AI���g�ڸ��ИI��ء�
���ƏV��