
ժҪ
�������Ĵ��ڡ��ɱ��c���W�����ɠ��P�I�Q�����ӣ���ο����i���m��ģ��?����ͨ�^12헺���ָ�˵�����©�Y�Y�x�������������ģ�͵��挍�����m���ԡ�
һ���������Ƞ��γɠ����g�F꠵�Ч�ʺڶ�?
2025��ȫ����{�ô�ģ�ͳ�300�������x�����R��������:
��λ��y:�������L����token/page/char��Ϙ�ע
�ӑB���r:�r���{�����ڿ�����I��ُ����
ָ�˳��d:87%�Fꠟo�����������Wָ������1�֡��ĘI�Ճrֵ
�Y��:ƽ���x�����ڏ�30�����L��90�죬�Q�߳ɱ����300%��
��������©�Y�Y�x��:��300+ģ�͵���ƥ��
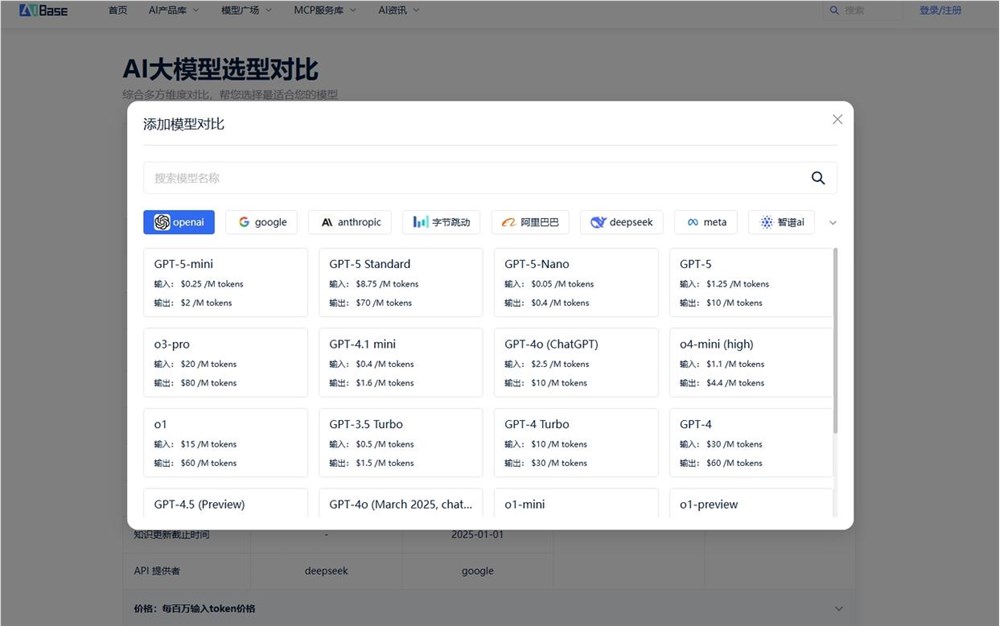
ͨ�^AIbase������C�ěQ��·��:
�������裨�ų�80%�x헣�
��
���ܵ�����C����������
��
߅�H���棨�u����r�����ԣ�
��Gemini2.5Flash-Lite��DeepSeek R1ʵ��Ϊ��:
�P�I����_�D������ͬ��2025-08-13��

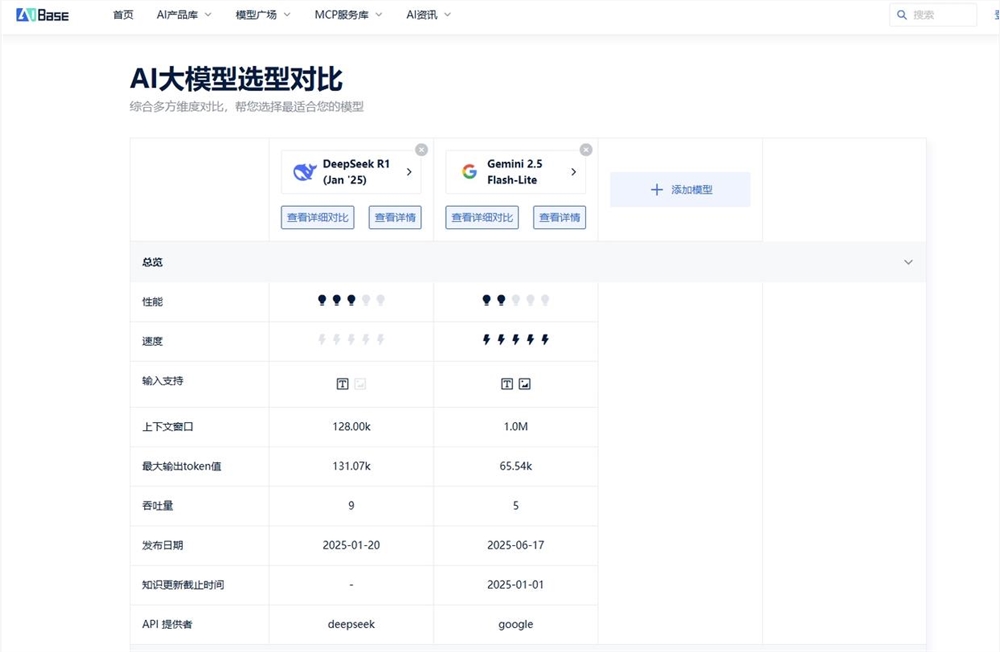
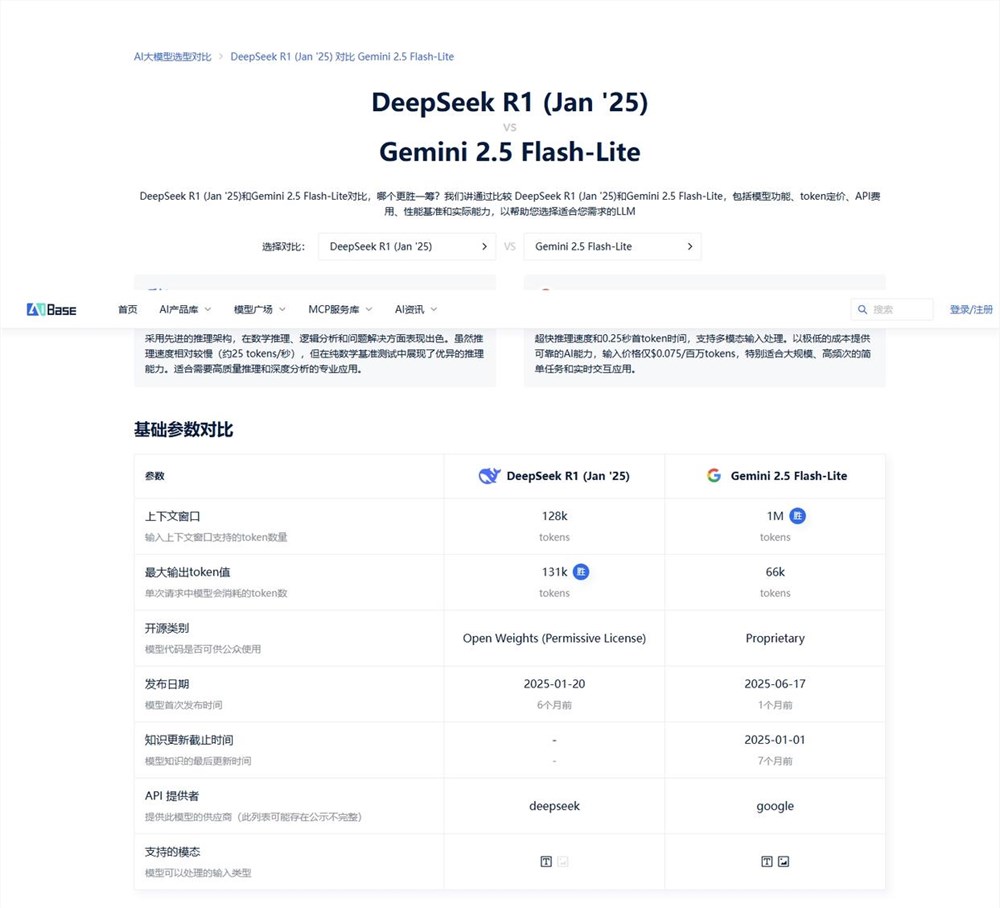
������I���Q�ߌ���:FAQ�C�����x��
����:200ҳ�����ֲ�������մ���10M tokens����Ӧ<2��
�Q��©�Y��Ч�^��:
1.���������^�V
�����ġ�200k �� ����12��ģ��
�ɱ���$0.5/M �� ʣ��3����Gemini���ף�
��Ӧ>100tok/s �� Geminiֱ�Ӵ��
2.���ܵ���C

3.߅�H����Q��
�xGemini:��ʡ$16��000����2��A100��
�xDeepSeek:����Ӌ������˹��}�˽���15%
�YՓ:��ҎFAQ�xGemini������ֵӋ���xDeepSeek
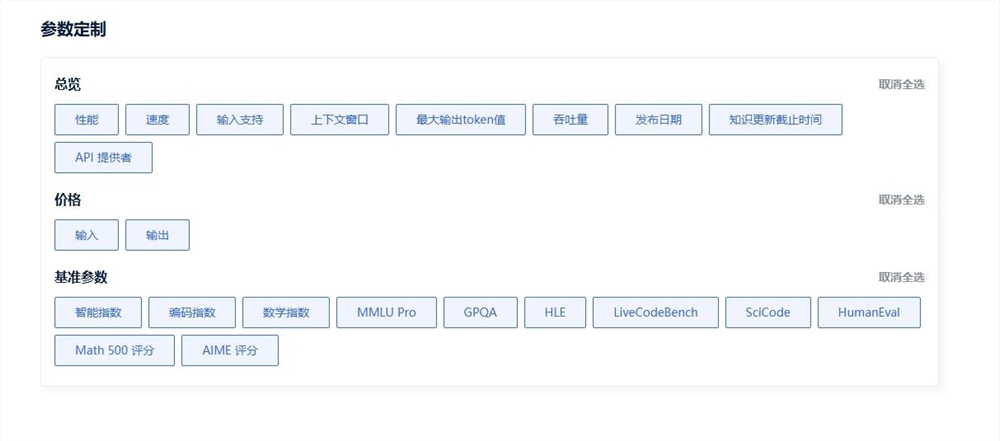
�ġ���Ό��F���}�õ��x�ͷ���Փ
1.��ģ�ͶԱ�ƽ̨�� �趨��������/�ɱ�/������������ֵ
2.���ɄӑBPDF��棨���ɱ�ģ�M������
3.Ƕ���Ʒ�����ĵ��� ����ѡ�ͻ���
ij�羳����Ŷ���֤:��3Сʱ����ѹ����18���ӣ�����ѡ�����½�40%
�塢���߃rֵ�ı��|:���Q���p
�����g�x�͏ą�����Փ�D�������C:
���̎��YԴ�۽���ʾ�~�������Dž�����У��
�汾�����r���ݕ�ʷ�Q������
�ɱ������Ԅ��|�l�����u������r�ӳ�15%��
�Q��Ч�ʹ�ʽ:
��ģ�������� ����ά�ȣ��� ���������� = ��ִ�нYՓ
��AIbase �ѡ��ۺ϶ά�ȶԱȡ����3����ť������������Ϊ��˾��ʡ����ʦ����ʱ�䡣
�����3С�r���h�s�̵�10���R���F��ܰѾ���������ʾ�~�����c�bƷ�w�����nj������������ܡ�
���e��